
һ������ģ�͵ļ��ֳ�����ʽ�������ѡ��
�������ᡡҪ����Ŀ�ġ�չʾһ������ģ��(GLM)�ij�����ʽ�����ص㣬�������Ǻ���ѡ�á�������ͨ���ı���ƾ���X������Э������Ľṹ�Լ�������ƾ���X�ı������ʣ���GLM�����һ���������˵ľ������ʽ���������GLM�������ڻع�����������Э�����������ˮƽģ�͵Ⱦ����ͳ��ģ�͡����ۡ�����ѡ��ͳ��ģ�͵Ĺؼ�����Ū��������ȡ�Ե�������ͣ�Ӱ�����غͷ�Ӧ���������ʣ�����Э�����Լ�����ͳ��ģ�͵����÷�Χ��
Common Patterns and Rational Applications of the General Linear Model
Hu Liangping,
����Department of Medical Statistics,Academy of Military Medical Sciences(100850),Beijng
������Abstract����Objective��Presenting the common patterns and their characteristics of the general linear model(GLM)for the convenient and rational application.Methods��By changing the structures of design matrix(X)and covariance matrix of error(��) and analyzing the characters of variables in the design matrix(X),some concise and concrete expressions are deduced from GLM respectively.Results��To simplify GLM into several particular statistical models which are suitable for regression analysis,analysis of variance and covariance,and multilevel modelling.Conclusion��The key to the rational selection of statistical models lies in clarifying the design types of data,the characters of affecting factors and response variables,the availability of covariates,and the applicability of various statistical models.
������Key words����General linear model��Design matrix��Covariate matrix��Multilevel model
����һ������ģ����
����ͳ�Ʒ����Ķ�����ͳ�����ϣ���������а������Ա���X�������仯�ķ�Ӧ����Yʱ��Ϊ��������ķ�ʽ������Ӧ�������Ա���֮��������ϵ��������ѡһ������ģ��(GLM)����ʽ(1)��
Y=X��+e
(1)
����ģ��(1)�У�YΪ��Ӧ�����Ĺ۲�ֵ������XΪ���Ա����������ƾ���Ϊ�ع����������eΪ��̬�������������������ٶ����ֵE(e)=0��Э�������Ϊ��=Cov(e)��
��������ģ��(1)�����GLM���и��ֲ�ͬ�ṹ����ƾ���X������Э�������ʱ��GLM�ͻ��и��ֲ�ͬ�ı��Ρ����磺����=��2Inʱ��ģ��(1)����Ϊ����(���)���Իع�ģ�ͣ�����ɽ�X�ʷֳ�X=(X1,X2)������X1��̶�ЧӦ�йأ�X2�����ЧӦ�йأ�ͬʱ��������ʽ(2)����ʽ��
��=X2VX��2+��
(2)
����ʽ(2)��V�ͦ���Э���������ģ��(1)�ͱ��һ�����Ի��ģ��(GLMM)�������X�릸������һЩ�ٶ���ģ��(1)�ɷֱ�ת���MANOVAģ��(����Ԫ�������ģ��)��GMANOVAģ��(�������Ԫ�������ģ��)��ģ�͡�1����
�����ӹ�����ƾ���X�ı������������࣬ģ��(1)�������ͬ�ı��Ρ����磺��X�ֱ��ɹ̶�ЧӦ�����ЧӦ�̶����������ЧӦ�Ķ���Ӱ�����ع������ʱ��ģ��(1)�ͷֱ��Ϊ�̶�ЧӦ�����ЧӦ�ͻ��ЧӦ�ķ������ģ�ͣ���Xȫ���ɶ�����Ӱ������(�����Ʊ���)�������ʱ��ģ��(1)�ͼ�Ϊ�ع����ģ�ͣ���Xͬʱ�ɶ��ԺͶ�������Ӱ�����ع������ʱ����������������������ۣ�����һ�������Ե�Ӱ�������ǹ̶�ЧӦʱ��ģ��(1)�ͱ����Э�������ģ�ͣ����ζ��������Ե�Ӱ�����������ЧӦʱ��ģ��(1)�ͱ���˶�ˮƽ�ع�ģ��(������ϵ��ģ�ͻ�ֲ�ģ��)��1��3�����������������Ե�Ӱ�����ذ����̶����������ЧӦʱ�����̶�ЧӦ�Ķ��Ա���δ���Ʊ�������������ģ��(1)�ͱ���˾���Э��������ṹ�Ķ�ˮƽģ�ͣ���֮��ģ��(1)�Ծ��Ƕ�ˮƽ�ع�ģ�͡�
����GLM�����ļ���ʽ
����1.�������ģ��
����(1)�̶�ЧӦ�������ģ�ͼ�Fͳ����
�������ڶ�����ʵ��������ͺܶ࣬�����������������Ϊ��(��ͬ)����̶�ЧӦ����A��B�ֱ���a��b��ˮƽ������a��b��ˮƽ��ϣ�������¾��ظ�k(k��2)��ʵ�飬YΪ�����ķ�Ӧ�������������������������ƶ�Ӧ�ķ������ģ����ʽ(3)������
yijk=��+��i+��j+(�Ӧ� )ij+eijk
(3)
i=1,2��,a;j=1,2,��,b;k=1,2,��,n��
����ģ��(3)�У�������ƽ��ЧӦ����i������A��i��ˮƽ��ЧӦ(����i=��Ai-��)����j������B��j��ˮƽ��ЧӦ(����j=��Bj-�̣�(�Ӧ¡�)ij��A��B�ֱ��ڵ�iˮƽ���jˮƽ��������µĽ������õ�ЧӦ��eijk���������������
�������з������ʱ����Ҫ�����Fͳ�������䷽�����Ƶ�������A��B����������A��B������������������ף�4�ݡ������������������ı���ʽ����������顰H0:��i=0,H0:��j=0,H0:(�Ӧ¡�)ij=0��һ��i,j��������Fͳ��������ʽ(4)��
FA=MSA/MSE��FB=MSB/MSE��FAB=MSAB/MSE
(4)
����ʽ(4)�У�FA��Fa-1��ab(n-1)�ֲ���FB��Fb-1,ab(n-1)�ֲ���FAB��F(a-1)(b-1),ab(n-1)�ֲ���
����(2)���ЧӦ�������ģ�ͼ�Fͳ����
�������ij���ص�ˮƽ�Ǵӽϴ�����������ѡȡ�ģ���ô�����ڸ����ص��ƶϽ�������о��������ȫ��ˮƽ����Ч������������Ϊ���ЧӦ���ء��������������������Ϊ�������о����ЧӦ�������ģ�͡�����������ģ��(3)�ġ������������У����̶�ЧӦ����A��B��Ϊ���ЧӦ���أ������������䣬��ʱ���������ϵ�ģ�ͼ�ʽ(5)��
yijk=��+��i+��j+(�Ӧ� )ij+eijk
(5)
i=1,2,����a;j=1,2,��,b;k=1,2������n��
����ģ��(5)�У�������ƽ��ЧӦ����i,��j,(�Ӧ� )ij�Լ�eijk��������������ر�أ��ٶ���i��NID(0���Ҧ�2)����j��NID(0���Ҧ�2)��(�Ӧ� )ij��NID(0���ҦӦ�2)��eijk��NID��0����2)��
�������ǣ���һ�۲�ֵ�ķ����ǣ�
V(yijk)=�Ҧ�2+�Ҧ�2���ҦӦ�2����2
(6)
����ʽ(6)�еȺ��ұ�������������������ģ��(5)�ֳ�Ϊ�������ģ�͡�
�������ڷ������ģ�ͣ�����Fͳ�����ķ��������Ƶ���A��B��A��B������������������ף�4�ݡ������������������ı���ʽ����������顰H0�æҦ�2=0;H0�æҦ�2=0;H0�æҦӦ�2=0��������Fͳ����(��Ϊ�����ЧӦ������˵��������ڸ�������ЧӦ�ļ�����û�������)����ʽ(7)��
FA=MSA/MSAB
����FB=MSB/MSAB
����FAB=MSAB/MSE
(7)
����ʽ(7)�У�FA��Fa-1,(a-1)(b-1)�ֲ���FB��Fb-1,(a-1)(b-1)�ֲ���FAB��F(a-1)(b-1),ab(n-1)�ֲ���
����(3)���ЧӦ�������ģ�ͼ�Fͳ����
����������AΪ�̶�ЧӦ������BΪ���ЧӦ����ʱ��������������������������ϵ�ģ�ͳ�Ϊ���ЧӦ�������ģ�ͣ���ʽ(8)
yijk=��+��i+��j+(�Ӧ� )ij+eijk
(8)
i=1,2,��,a;j=1,2,��,b;k=1,2��,n��
����ģ��(8)�У���i�ǹ̶�ЧӦ����j�����ЧӦ�����Ҽٶ�(�Ӧ� )ijҲ�����ЧӦ����eijk����������ٶ���iʹ�æ�ai=1��i=0����j��NID(0,�Ҧ�2)��(�Ӧ�)��ij��N(0����2�Ӧ�)��eijk��NID(0,��2)��(�Ӧ� )ij�Ķ����Բ������ܳ�������Ϊ��ai=1(�Ӧ� )ij=(�Ӧ�).j=0,j=1,2,����b������ζ�ţ��̶����صIJ�ͬˮƽ�ϵ�ijЩ��������Ԫ�ز��Ƕ����ġ���
��������ģ��(8)�ķ�����������������������������Fͳ����������A��B��A��B������������ʽ��������ף�4�ݡ����ڹ̶�ЧӦ�ļ������ΪH0�æ�i=0���������ЧӦ�ļ������ΪH0�æҦ�2=0;H0�æҦӦ�2=0����ʱ��ǡ����Fͳ������ʽ(9)��ʾ��
FA=MSA/MSAB
����FB=MSB/MSE
����FAB=MSAB/MSE
(9)
����ʽ(9)�У�FA��Fa-1,(a-1)(b-1)�ֲ���FB��Fb-1,ab(n-1)�ֲ���FAB��F(a-1)(b-1),ab(n-1)�ֲ���
����2.�ع����ģ��
������ģ��(1)����ƾ���Xȫ�ɶ�����Ӱ������(�������Ʊ���)�������ʱ�����ͼɵ����Ļع����ģ��(10)��
yi=��0+��1X1+��2X2+����mXm+ei
(10)
i=1,2,��,n��
����ģ��(10)�IJ������ơ�����������������ͨͳ��ѧ�̿����ж�д�ú���ϸ���˴���������
����3.������Э�������ģ�����ˮƽģ��
����(1)������Э�������ģ�͡�4��
��������������Ӫ����ֵ�������У�������ϵ�����(��Ϊ����A)������a�֣�ÿ�����Զ����ƽ����ʳ��(X)����ƽ������������(Y)����Ӱ�졣����A�ǹ̶�ЧӦ��Ӱ�����أ�X�Ƕ�����Ӱ�����أ�Y�Ƕ����Ĺ۲�������ȫ�����Զ�����ȫ����ط������a����������ȥ������������ռ��������Ͽ�������ĺ�һ��Э�����ĵ�����Э�������ģ��(11)��������
yij=��+��i+��(xij-x..)+eij
(11)
i=1,2,����a;j=1,2,��,n��
����ģ��(11)��yij�ǵ�i��������ȡ�õķ�Ӧ�����ĵ�j���۲�ֵ��xij�Ƕ�Ӧ��yij��ƽ����ʳ����x..��ȫ��xij��������ֵ��������yij��Ӧ����ƽ��ֵ����i�ǵ�i�����ϵ�ЧӦ�����ǻع�ϵ����eij��NID(0,��2)����������������ǣ�����H0�æ�i=0��Fͳ������ʽ(12)��
FA=��(SS��E-SSE)/(a-1)��/��SSE/��a(n-1)-1����
(12)
����ʽ(12)�У�FA��Fa-1,a(n-1)-1�ֲ���SS��E=1yy-(1xy)2/1xx,SSE=Eyy-(Exy)2/Exx�����⣬1xx��1yy��1xy�ֱ�Ϊx,y,x��y���������ƽ���ͼ�������֮�ͣ�Exx,Eyy,Exy�ֱ�Ϊx,y,x��y�����������ƽ���ͼ�������֮�͡�
����(2)��ˮƽģ�͡�2��3��
������ǰ����������Ӫ����ֵ�������У�����ɹ�ѡ�õ������гɰ���ǧ�֣���Ӵ������������ѡȡa������ǰ���������о�������������䡣��ʱ���о���Ŀ������a�����ϵ�������Ϣȥ�Ʋ���ǧ�����������ɵ�������y��x�仯�������ϵ������������ϼ����Խ����Ӱ�죬ģ��(1)һ�¼ɼ�ֱ�ع�ģ�ͣ�����ģ�������ϼ�ı����Dz��ɺ��Ե�����£��ü�ֱ�ع�ģ���������Ǻܲ����ġ���ʱ������һ������Ϊ��ˮƽ��(�����ϵ��)ģ��(13)�Ǻܺ��ʵġ�
yij=ai+bixij+eij
(13)
i=1,2,��,a;j=1,2,��,n��
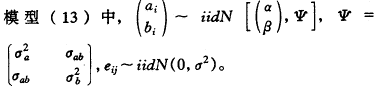
�����˴����ؾ�ai��б��bi�������ϵ���������·ֱ�Ϊ����ؾ��б�ʣ���Ϊ���ϵ��ai��bi��Э�������eij����̬�������������ai=��+a��i��bi=��+b��i�����У�a��i��b��i�ֱ�Ϊ�ؾ��б�ʵ�������֣���ģ��(13)���ģ��(14)
yij=��+a��i+(��+b��i)xij+eij
����=��+��xij+(a��i+b��ixij)+eij
(14)
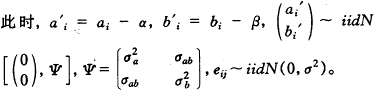
����eij��Ϊ���Զ�������(���һˮƽ��)������a��i+b��ixij��ӳ������֮��(��ƶ�ˮƽ��)�����ʳ�ģ��(14)Ϊ��ˮƽģ�͡�
����(3)���������ӵ�Э�������ģ�����ˮƽģ�͡�3��5��
���������й̶�ЧӦ�ķ������ģ���У�������Э���������Ӧ��ͳ��ģ�;ͳ�Ϊ��Ӧ��ƵĶ�ԪЭ�������ģ�ͣ����̶�ЧӦȫ��������ЧӦ(���Բ���ijЩ�̶�ЧӦ�������Ʊ����������Դ���)�����ң���Щ���ЧӦ������Ƕ��ϵ(�磺ѧУ���༶����ʦ��ѧ��)ʱ�����Ӧ��ͳ��ģ�;ͳ�Ϊ��ˮƽģ�ͣ������в��̶ֹ�ЧӦ����δ���Ʊ���������������ʱ��ģ�;��Ǿ��ж�ԪЭ��������ṹ�Ķ�ˮƽģ�͡�
����GLM���ֱ��εĺ���ѡ�á�3,4��
��������1���о�Ӱ��ij��ҩ�����������ء����ѡȡ4̨��������ҩ��Ļ�����3λ������ʦ���������Ƴ���ͬһ����ҩ��İ��Ʒԭ�Ͻ������µ����顣ÿλ��ʦ��ÿ̨�����ظ�2�����飬�۲�ÿƬҩ�������(�����۲�ֵ)���������ϴ��ԣ��ٶ�����������̬�Ժͷ�������(��ͬ)����ѡ����ʵ�ͳ��ģ�ʹ������ϡ�
��������2��Ϊ̽��ij��ѧ��Ӧ���¶Ⱥʹ��������ʵ�Ӱ�죬�о�������Ԥ����Ľ����ѡ����4���¶�(70��80��90��100��)��3�ִ���(�ס��ҡ���)�������������п��ܵ��������ͬ�����¶��ظ�2�����飬�۲�ÿ�����������(�����۲�ֵ)���������ϴ��ԣ���ѡ����ʵ�ͳ��ģ�ʹ������ϡ�
�������������𡿴���ʽ�Ͽ�����1����2����ͬ�ġ�����ϸ��ĥ�����ѷ��֣�����֮����������ġ�����1�У���������һ̨������ҩ��Ҳ��������һλ��ʦ����������������ÿƬҩ���������������ȡ�����ʵ�ϣ���ҩ������������ܾ�����ȣ���Ϊ����֮��ͼ�ʦ֮�䶼���ڸ�����졣����ÿ̨������ÿλ��ʦ�������ѡȡ�ģ��Ҷ�ҩ������Ӱ�������ֵ����ͬ�ģ��ʻ����ͼ�ʦ������Ϊ���ЧӦ���أ��ʺ�ѡ������������������ЧӦ�������ģ��(5)�������ϡ�
����������2�У���ͬ�¶ȺͲ�ͬ���������µIJ��ʿ��ܻ����ܴ�չ���������Ŀ�ľ���Ҫ�ҵ���������ѵ�ˮƽ���䣬������û����������ÿ�����õIJ���Ӧ��ȡ�Ҳ����˵�����������������漰��4���¶ȵ�ЧӦȥ�Ʋ�����¶ȵ�ЧӦ��ͬ�����Դ���Ҳ����ˡ��ڱ����У����¶Ⱥʹ�����Ϊ�̶�ЧӦ��Ϊ���������ʺ�ѡ��������������ƹ̶�ЧӦ�������ģ��(3)�������ϡ�
��������3����ij�й���10�����أ�ij����ͼ�о�����10��������������Ѫ��IgEƽ��ˮƽ֮��IJ����������������ʱ�����ǵ��������̳��̿�����һ����Ҫ�Ķ���Ӱ�����ء��ٶ������н��������ء����̺�IgE3���������������ϴ��ԣ���ѡ����ʵ�ͳ��ģ�ʹ������ϡ�
��������4��ij�о��ߴ�һ����ڶ�ͯ������ȫ���Ե�������������س�ȡ��10�����ص����ϣ�ϣ���о�����Ѫ��IgE��ˮƽ�ߵ��뻼������֮��������ϵ���ٶ������а����ı�������3��ͬ���������ϴ��ԣ���ѡ����ʵ�ͳ��ģ�ʹ������ϡ�
�������������𡿴��Եؿ�����3����4���˵�ӡ��������˵����ȫ��һ���¡���ʵ��Ȼ������3�У�10�����صĵ�������ȫ�����ˣ���������һ���̶�ЧӦ���أ��о�Ŀ���ǿ���������������Ѫ��IgEƽ��ˮƽ֮��IJ���������������壬��ͬʱ�������������̵�Ӱ�죬����ѡ�õ�����10ˮƽ������ϵ�Э�������ģ��(11)��
����������4�У�����������������ȫ�����ٸ����������ȡ��10�����ص�������������������Ѫ��IgEֵ�����뻼���IJ����йأ�Ҳ��һ���̶��������������ص�Ӱ�졣Ҳ����˵������֮��IJ����һˮƽ�ϵ���������֮��IJ���Ƕ�ˮƽ�ϵ���������Ŀ����ϣ������10����������ȥ�Ʋ�ȫ���������ص�������ʷ����������ʺ�ѡ�ö�ˮƽģ��(14)����ƪ�����ޣ�����ͳ��ģ�͵�Ӧ��ʵ�����ԡ�
�����֡���
����GLM��ͳ��ģ����ʹ��Ƶ����ߵģ���Ϊ���ж��ֲ�ͬ�ı��Σ��ɷֱ�������t���顢��������������ϵķ����Э����������ع�����Ͷ�ˮƽģ�͡���Ը���ʵ�����ϣ�����Ӧѡ��ʲôͳ��ģ�����������ʣ�����һ��ʮ�ּ��ֵ����⡣����Ϊ��ˣ���ҽѧ���к�ҽѧ�ڿ��У����dz�����ͳ�Ʒ��������������˿��й����Ŀ�ѧ�ԡ�7��9����
������ʵ�ϣ�����ͳ��ѧ����ʮ�ַḻ�����˿�ѡ��GLM�� GLMM�⣬��ʱ����ѡ�ù�������ģ�͡��������Ի��ģ���Լ���Ӧ�ķ�����ģ�͵ȡ����ڴ��۸��ӵ�ͳ�����Ϻ�ǧ����ͳ��ģ�ͣ���ʹ��ͳ�ƹ����ߣ�Ҫ����ʱʱ���ܺ�������ͳ��ѧ������Ҳ�����¡�������Ϊ������ѡ��ͳ��ģ�͵Ĺؼ�����Ū��������ȡ�Ե�������ͣ�Ӱ�����ص�����(�̶������ЧӦ)������Э��������Ӧ����������(����������������)�ͷֲ�����Լ�����ͳ��ģ�͵����÷�Χ�������������ݼ���dz�����������һ©��������Ƿ��֮����ֻ��������������ͬ���Ƕ��ҹ���ѧ�о�����������ͳ��ѧӦ�÷����ձ���ڵ�������㹻���Ӻ�ע�����ڴﵽ��ש����֮Ŀ�ġ�
���������
����1.Timm NH�� Mieczkowski TA. Univariate �� Multivariate General Linear Models��Theory and Applicatious Using SAS Software�� North Carolina�� SAS Institute Inc.1997��1��4��419��485.
����2.Goldstein H. Multilevel statistical Models. Second Edition�� London��Edward Arnold.1995��1��40.
����3.Littell RC�� Milliken GA�� Stroup WW�� Wolfinger. RD��SAS System for Mixed Models.North Carolina�� SAS Institute Inc.1996��87��227��253��265��423��502.
����4.Montgomery DC. Design and Analysis of Experiments.���ʹ�����������.ʵ����������.�������й�ͳ�Ƴ����磬1998��222��252.
����5.Singer JD. Fitting Multilevel Models Using SAS PROC MIXED. Multilevel Modelling Newsletter��1998��10(2)��5��8.
����6.����ƽ����.�ִ�ͳ��ѧ��SASӦ��.����������ҽѧ��ѧ�����磬1996��129��145.
����7.����ƽ.ҽѧ��������ҩ���۵ȹ�����һ�����ɺ��ӵ����⡪�����Ӻ�����ͳ��ѧ.����ҽѧ��ѧԺԺ����1996��20(3)��202��205.
����8.����ƽ�����ݸ�.ҽѧ�ڿ��г���ͳ�ƴ������.�л�ҽѧд����־��1998��5(2)��28��30.
����9.����ƽ.ҽѧͳ��Ӧ�ô�������������.����������ҽѧ��ѧ�����磬1999��1��105.
- �� ��ϰ��(2)
�� ����ָ��
�� ƽ���������ָ��
�� ��ϰ��(1)
�� X2�����ע������
�� X2����
�� �������X2����
�� ��ϰ��
�� ͳ��ͼ
�� һ������ģ�͵ļ��ֳ�����ʽ�������ѡ��



- ����
- ����
- ��
- ĸӤ
|
�� ��Ů�����ص� �� ��Ů������������ �� 2010�괦Ů������ �� ��Ů��Ů�˵İ��� �� �����Ů��Ů�� �� ��Ů��Ů�˵��ص� �� ��Ů��Ů�� �� ��Ů������ϲ����Ů�� �� ��ζԸ���Ů������ |

|
�� ���������ž� �� ʲô�ǻ��� �� ʲô������ �� ʲô�Ǹ����Ա����Թ�ͷ�ף� �� ǰ������� �� ��Ƥ���������ÿ��������� �� ��й�Dz��Ǹ���Ƥ�����йأ� �� ��й�����侫������? �� �����侫��ʲô���� |
|
�� Ů�Ծ����мǽ��̲赲������ �� �����е�һ�λ����� �� һ����å�ͼ�Ů�Ĺ��� �� ��Ψ����10���й���ʫ �� ��������� ����������� �� ���˱����˽�Ů�˵�һЩ�� �� ��Ů���ѱ��쵼��ȥ��� �� ���������˱������10��Ů�� �� ������Ϊʲô��СŮ�˵�ϲ���� |
|
�� ��������ι��Ӥ������ָ�� �� �����ȷʹ�ÿյ���֤���� �� �ñ������ܱ�ķ�������� �� ��Щ���������������� �� ���·���ʱ�Ѳ�4���� �� �����������Ի��в����� �� �������Ԥ��������ð�� �� ̥�̺�����Ĺ�������Ҫ�� �� �̡��ƺͿ��ȶ�̥����Ӱ�� |